ローカルLLMを構築
初めに
ローカルLLMを構築した際の記録です。
- LM Studio 0.4.12 (追記:2026/07/03)0.4.18 build 1
- Zed 1.0.0
- Foundary local 0.8.119
- AnythingLLM 1.12.1
(追記:2026/05/04)
- Codex app 26.506.31421
(追記:2026/05/16)
- Ollama 0.24.0
参考
けっこう実用的。「OpenCode」×ローカルLLMで“無料Claude Code”してみた | ギズモード・ジャパン https://www.gizmodo.jp/2026/05/opencode_google_gemma_4.html
OpenAI Codex / Claude codeでLocal LLMを実行 https://zenn.dev/edna_startup/scraps/e5f7e294b2ede3
Codex CLI 完全リファレンス #OpenAI - Qiita https://qiita.com/nogataka/items/d053468277b37c83ec3a
眠っているIntelのNPUをLLMで叩き起こしてみた https://pc.watch.impress.co.jp/docs/topic/feature/2096319.html
知識ゼロからAnythingLLMとLM StudioでRAG構築 https://qiita.com/junk1400/items/e2bc8c90993c123ac579
LM Studio と Zed でコーディング
LM Studio
インストール
自分の環境に応じたモデルをダウンロード
ローカルサーバーの設定
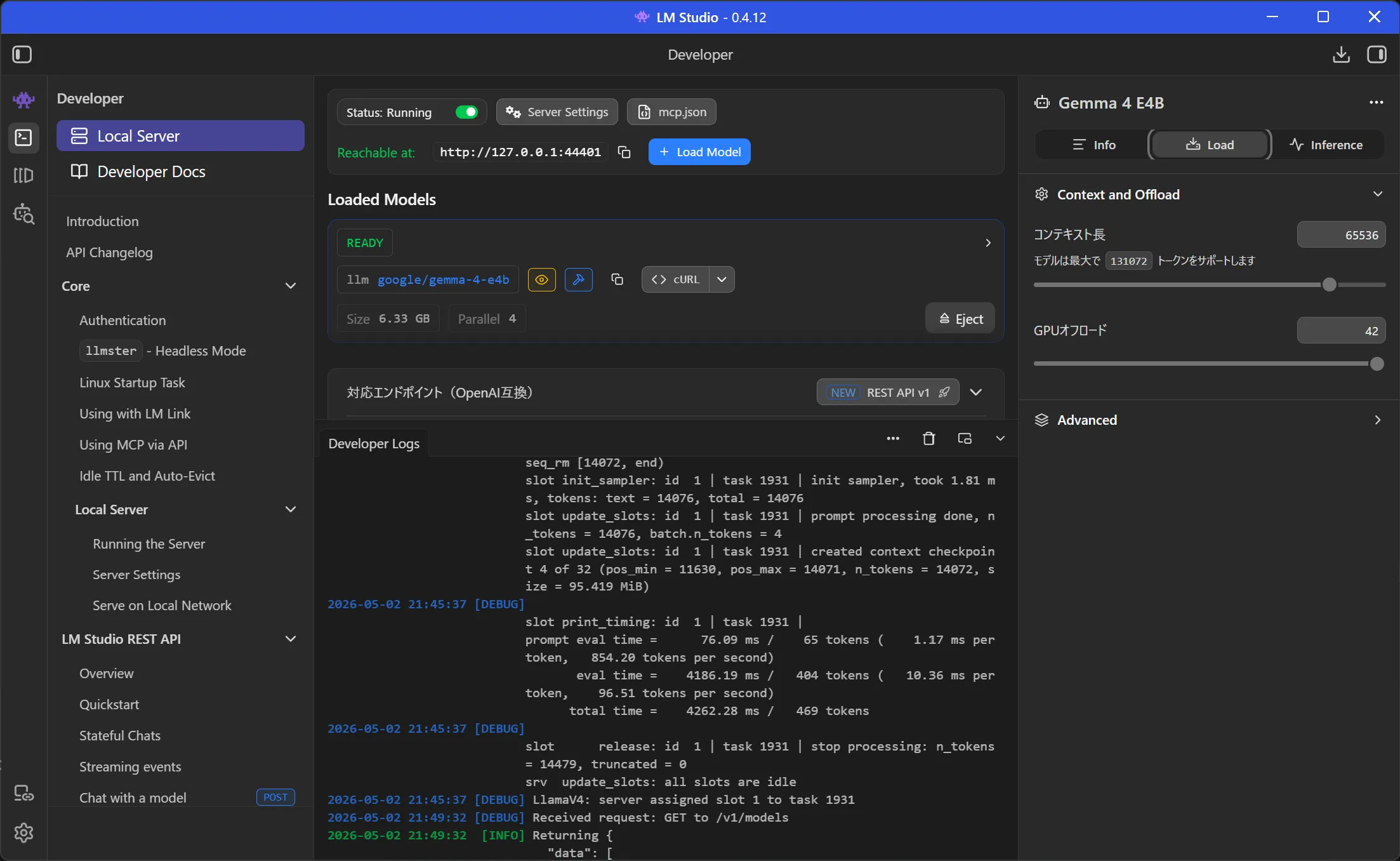
- 左に並ぶアイコンから Developer をクリック
- Status のところをクリックして Running にする
- Load Modelでモデルを読み込み
- 右パネルを開いてコンテキスト長を調整
URLを控えておく。上記だと http://127.0.0.1:44401
左下歯車アイコンから設定を開く
Developerの設定
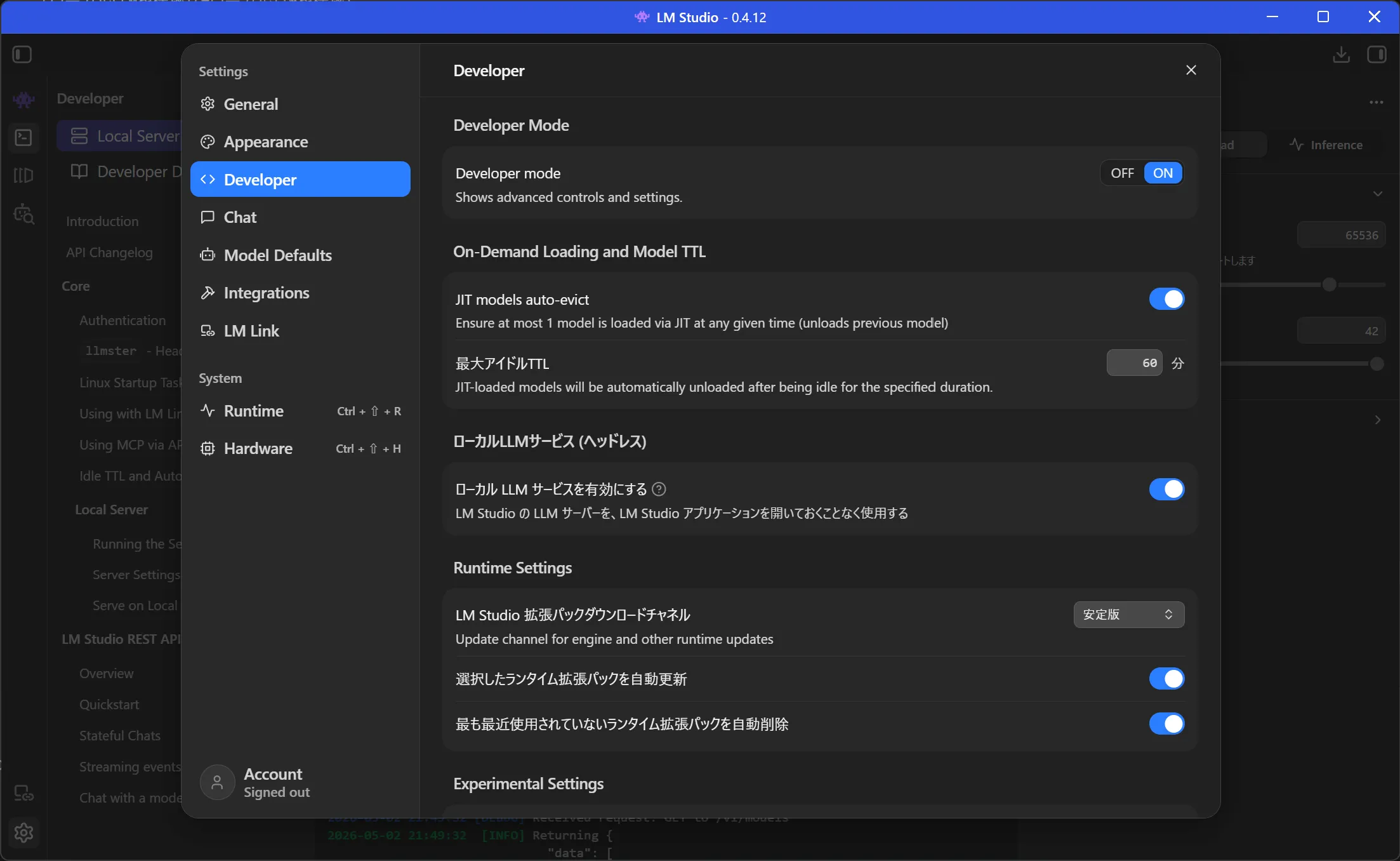
- ローカル LLM サービスを有効にする、をON
- スタートアップ登録されて、ログインごとにサーバーが起動するようになる
Zed
インストール
左下アイコン二つ目「Agent Panel」を開いて、パネル右上アイコンから設定開く
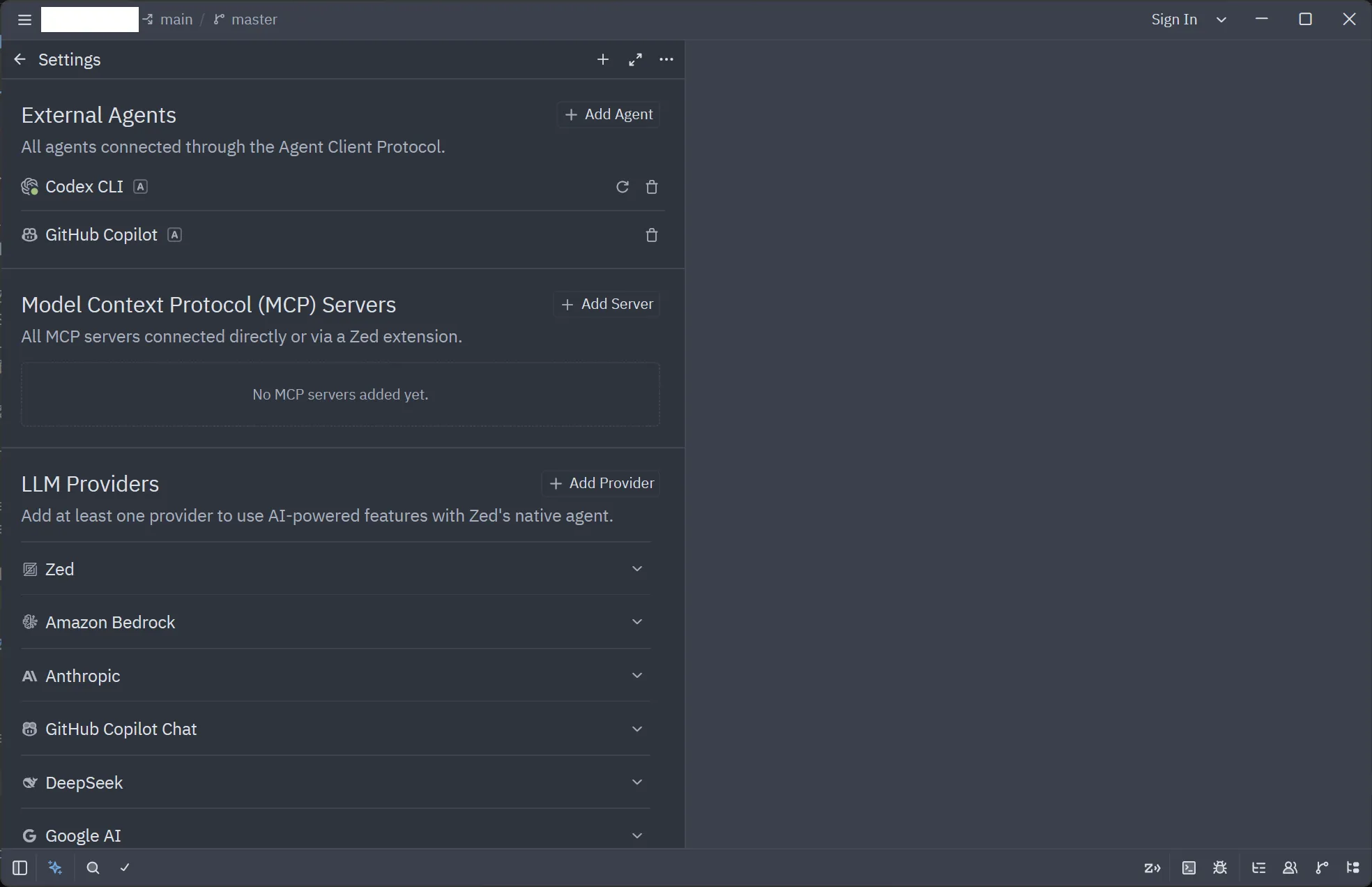
Add Agent ボタン → Install from Registory
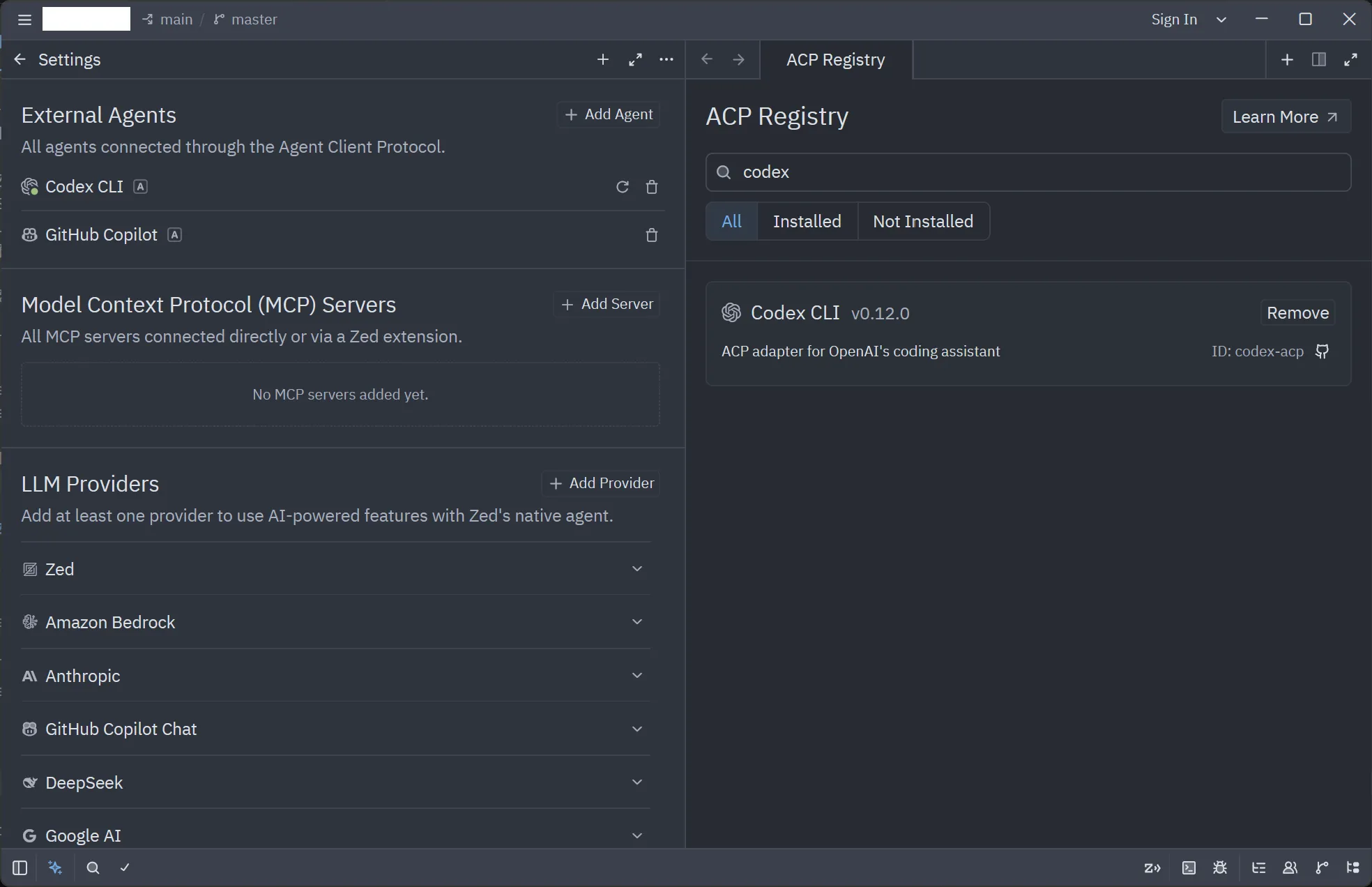
Codex CLI をインストール
次のファイルをテキストとして開く。なければ作る。
“C:\Users\<Windowsユーザー名>\.codex\config.toml”
中身にモデル名など追加。同名のキーがあるなら先頭 # でコメントにして残しておく方が無難。URLは /v1 追加
model = "google/gemma-4-e4b"
model_provider = "lmstudio-local"
[model_providers.lmstudio-local]
name = "LM Studio"
base_url = "http://127.0.0.1:44401/v1"
wire_api = "responses"設定に戻って、LM Studio のところにURLを入れる。なおここでは /api/v1
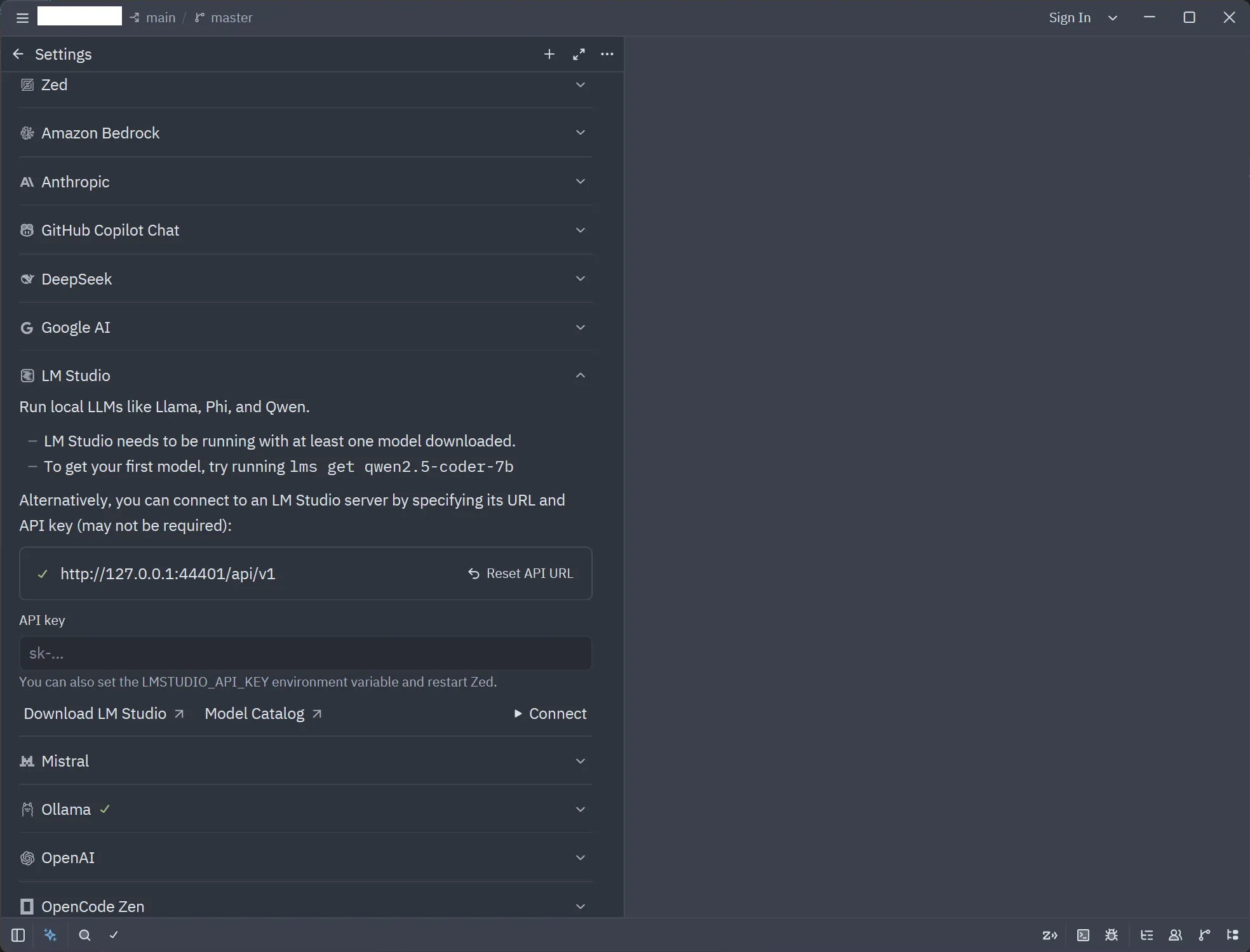 右下 Connect を押すとURLにチェックマークがつく。
右下 Connect を押すとURLにチェックマークがつく。
Zed を再起動
適当な作業フォルダを作り選択
Agent Panel を開く。
左上から「Codex CLI」を選ぶ
選択したモデルを選ぶ
Codex app の場合
(追記:2026/05/04)
本当は Zed から Codex CLI を使うのではなく Codex app を使いたかったが、現状不具合があって出来なかった。
“invalid_request_error” when passing tools with the type “namespace” using Codex and enabled MCPs https://github.com/lmstudio-ai/lmstudio-bug-tracker/issues/1810
(追記:2026/07/03)
前述の issue で更新されたとの事
LM Studio バージョン 0.4.18 build 1 で確認したところ動作した。 「適用可能な場合、API レスポンスで`reasoning_content’と content’を分離」はONにする。
config.toml に書く内容は Zed と同じ。ただし実行によって他の項目も追記される。
Foundly local と AnythingLLM で NPU 使用
ここではNPUに限った書き方をしますが、GPUやCPUのモデルでも可能です。
Foundly local
PowerShell で順に入力
winget install Microsoft.FoundryLocal
foundry model list --filter device=NPU
foundry model download DeepSeek-R1-Distill-Qwen-7B-openvino-npu:3
foundry model load DeepSeek-R1-Distill-Qwen-7B-openvino-npu:32026/05/02現在のNPU対応リスト
🟢 Service is Started on http://127.0.0.1:50373/, PID 24896!
🕚 Downloading complete!...
Successfully downloaded and registered the following EPs: NvTensorRTRTXExecutionProvider, OpenVINOExecutionProvider, CUDAExecutionProvider.
Valid EPs: CPUExecutionProvider, WebGpuExecutionProvider, NvTensorRTRTXExecutionProvider, OpenVINOExecutionProvider, CUDAExecutionProvider
Alias Device Task File Size License Model ID
-----------------------------------------------------------------------------------------------
qwen2.5-coder-0.5b NPU chat, tools 0.32 GB apache-2.0 qwen2.5-coder-0.5b-instruct-openvino-npu:4
---------------------------------------------------------------------------------------------------------------------------------
phi-4-mini-reasoning NPU chat 2.15 GB MIT Phi-4-mini-reasoning-openvino-npu:3
--------------------------------------------------------------------------------------------------------------------------
qwen2.5-0.5b NPU chat, tools 0.32 GB apache-2.0 qwen2.5-0.5b-instruct-openvino-npu:4
---------------------------------------------------------------------------------------------------------------------------
qwen2.5-1.5b NPU chat, tools 0.86 GB apache-2.0 qwen2.5-1.5b-instruct-openvino-npu:4
---------------------------------------------------------------------------------------------------------------------------
qwen2.5-coder-1.5b NPU chat, tools 0.87 GB apache-2.0 qwen2.5-coder-1.5b-instruct-openvino-npu:4
---------------------------------------------------------------------------------------------------------------------------------
phi-4-mini NPU chat, tools 2.15 GB MIT phi-4-mini-instruct-openvino-npu:3
-------------------------------------------------------------------------------------------------------------------------
qwen2.5-coder-7b NPU chat, tools 4.17 GB apache-2.0 qwen2.5-coder-7b-instruct-openvino-npu:3
-------------------------------------------------------------------------------------------------------------------------------
qwen2.5-7b NPU chat, tools 4.17 GB apache-2.0 qwen2.5-7b-instruct-openvino-npu:3
-------------------------------------------------------------------------------------------------------------------------
deepseek-r1-7b NPU chat 4.17 GB MIT DeepSeek-R1-Distill-Qwen-7B-openvino-npu:3
---------------------------------------------------------------------------------------------------------------------------------
phi-3-mini-4k NPU chat 2.13 GB MIT Phi-3-mini-4k-instruct-openvino-npu:2
----------------------------------------------------------------------------------------------------------------------------
mistral-7b-v0.2 NPU chat 3.60 GB apache-2.0 Mistral-7B-Instruct-v0-2-openvino-npu:2AnythingLLM
インストール
左下アイコンの一番右から設定を開く
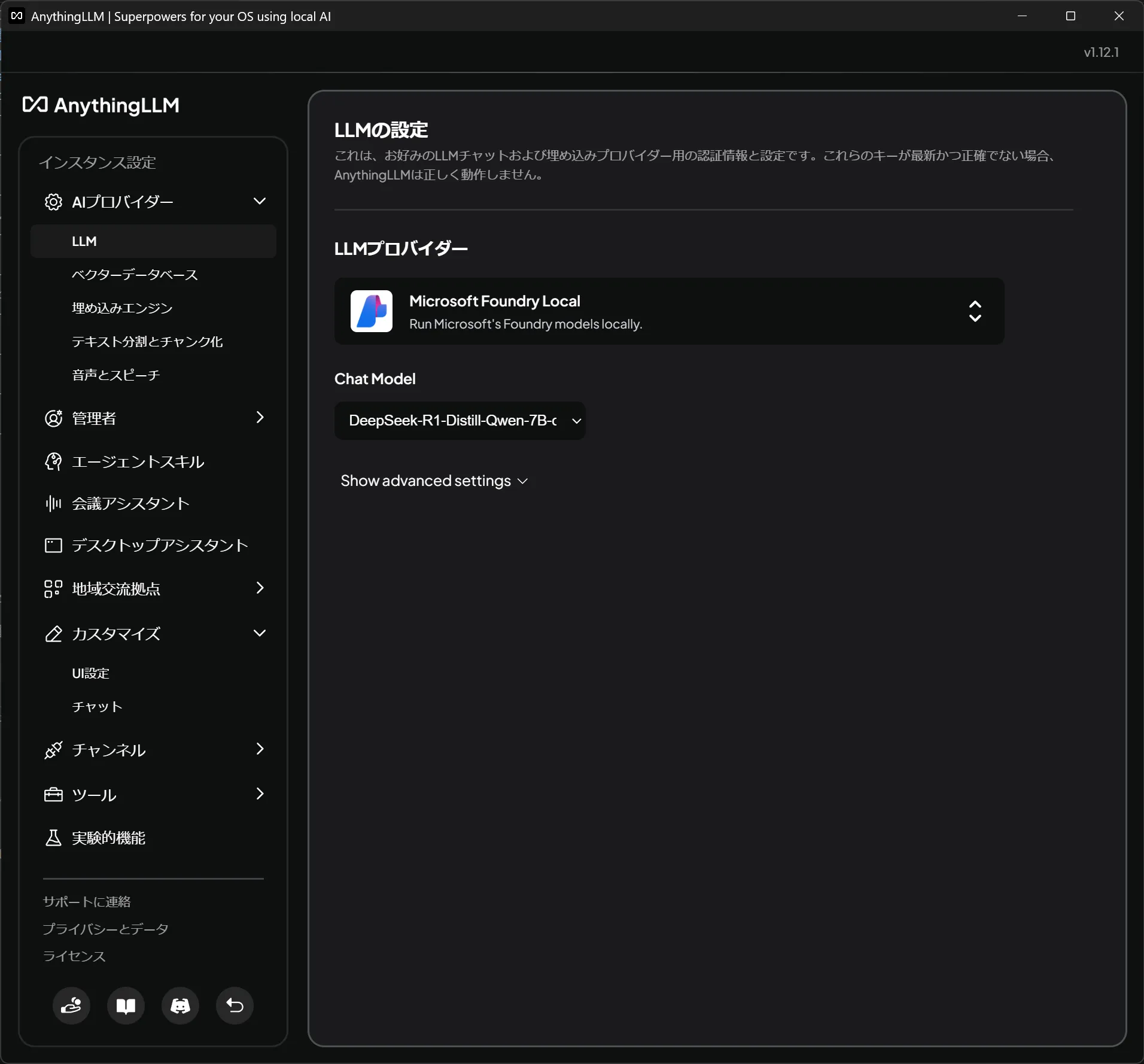
AIプロバイダー → LLM → Microsoft Foundly local
ChatModel を選ぶ
右上 Save changes を押す。ボタンは変更がある場合にしか出てこない。押すのを忘れがちなので気を付ける。
Ollama と Codex app
(追記 2026/05/16)
Ollama がローカルLLMに対応したという話を聞いたので試しました。
Codex app
Microsoft Store から codex と入れると出てきます。
サインインはしなくて良さそうです。
Ollama
Windows インストーラで入れました。
https://ollama.com/download/windows
インストール後
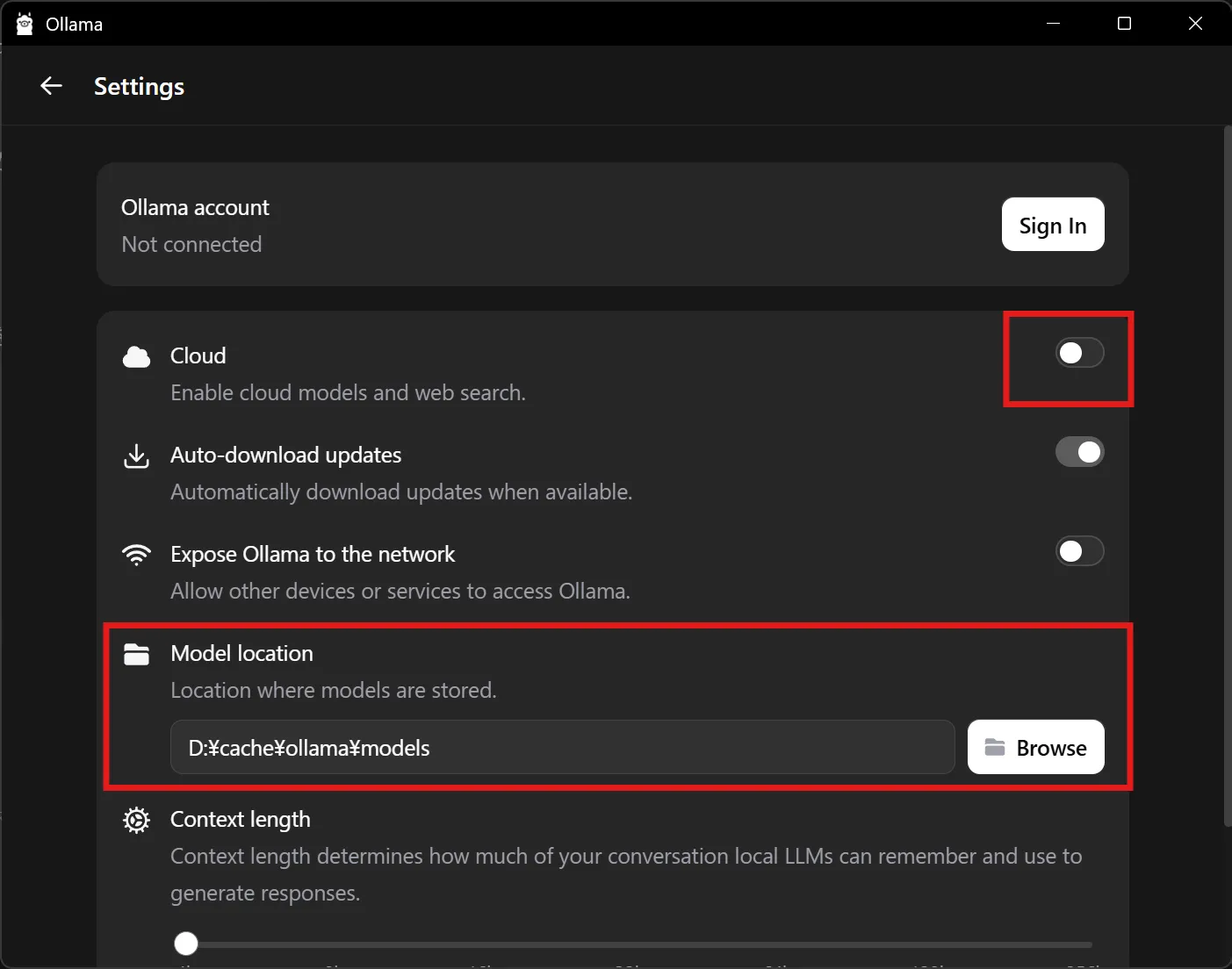
設定を変えました。ローカルLLMにしたいので Cloud をOFF。後はモデルのダウンロード先を空き容量が多いところに変えています。
後は指示にあるように PowerShell でコマンド実行
ollama launch codex-appモデルを選ぶぐらいです。
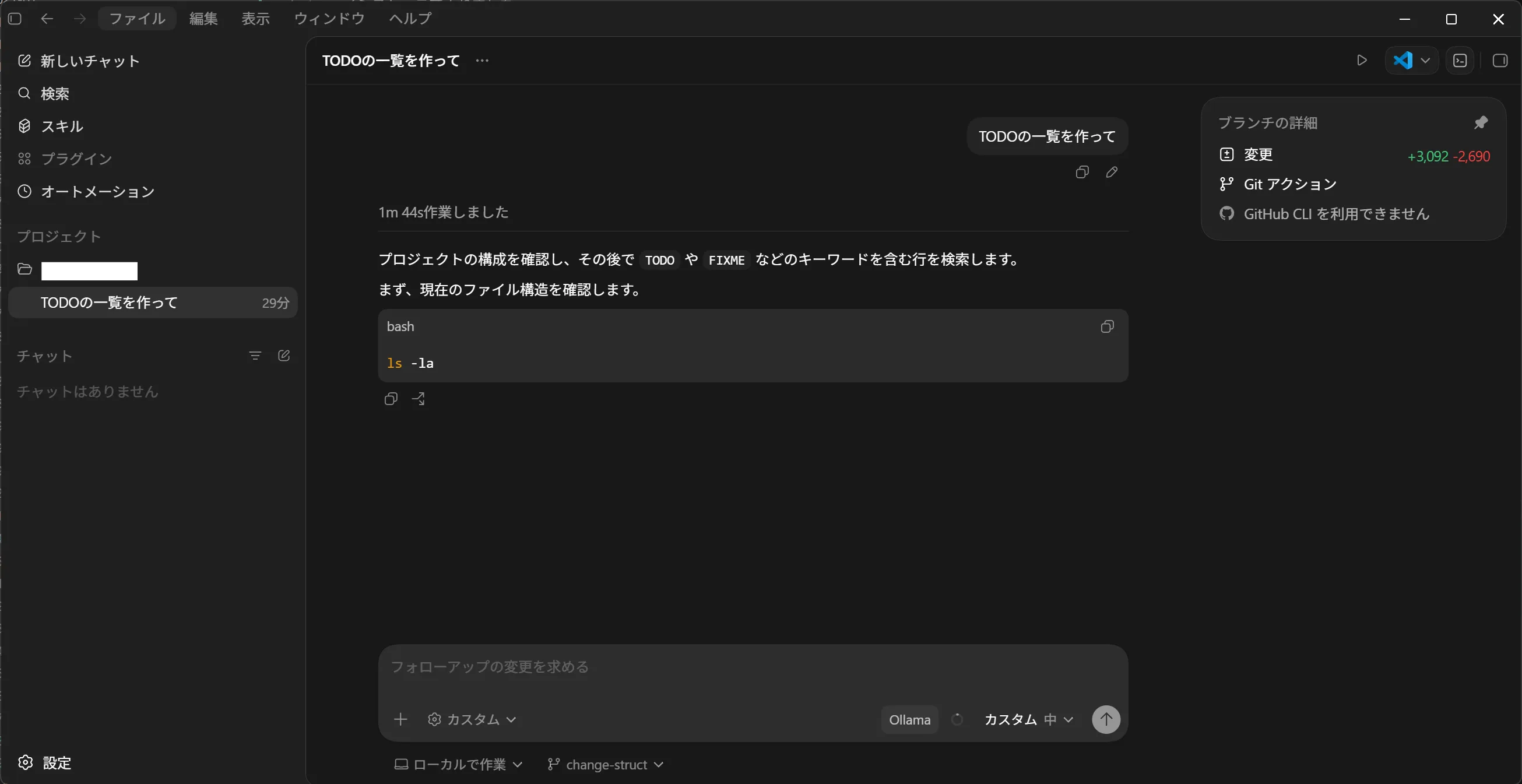
Codex app が起動してきます。
既にあるプロジェクトを開いて「TODOの一覧を作って」と指示してみました。
固まってしまいましたが動いてはいます。権限の調整が要りそうです。
後書き
色々試しましたが Ollama と Codex app が良さそうです。
(追記:2026/07/03)
不具合が直ったようなので、モデル選択や設定変更が柔軟な LM Studio と Codex app を使うことにします。